BriefGen-AI - Analisis Documental con IA
Aplicacion para analizar PDFs con Next.js, Express, LangChain y Google Gemini, devolviendo resumen, requisitos, stack y riesgos en formato estructurado.
Resumen Técnico
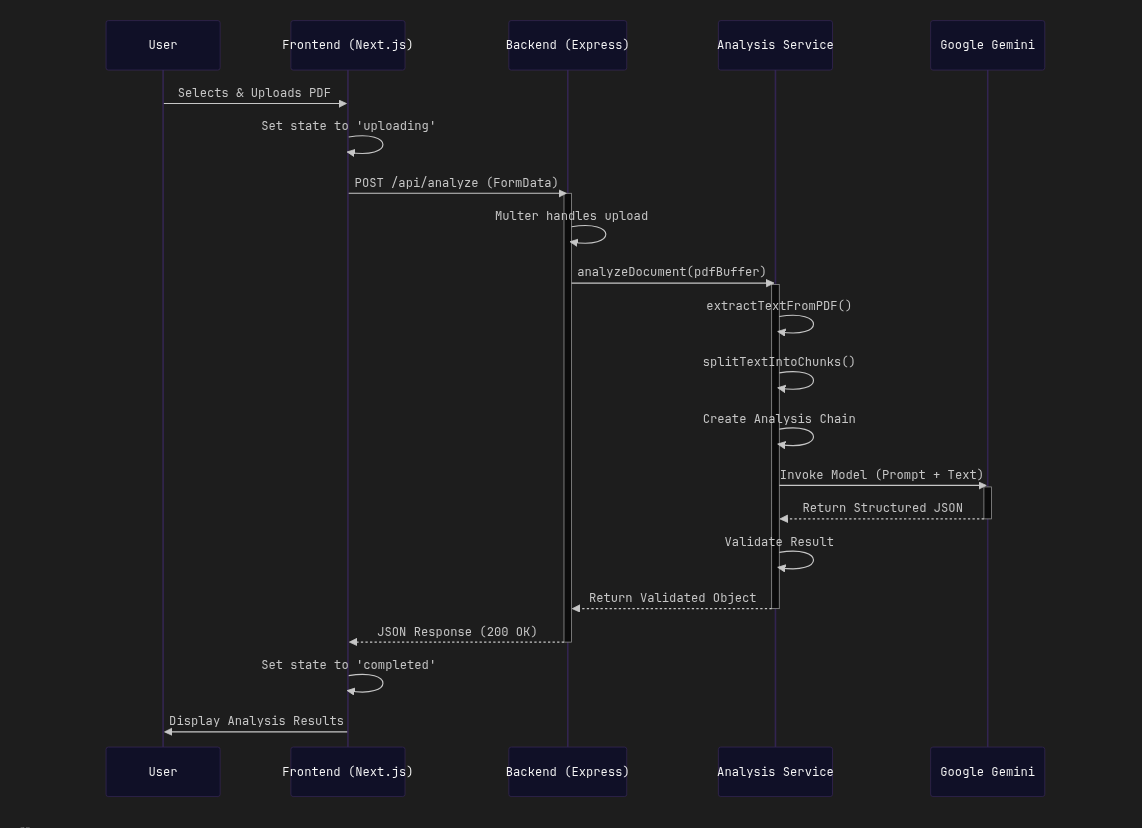
BriefGen-AI procesa documentos PDF como briefs, RFPs y documentos tecnicos para extraer informacion accionable. El frontend esta construido con Next.js 14, React 18, TypeScript, Tailwind CSS y shadcn/ui. El backend usa Node.js y Express para recibir archivos, validarlos, extraer texto, dividirlo en fragmentos con LangChain y consultar Google Gemini. La respuesta se normaliza como JSON con resumen, requisitos clave, tecnologias detectadas y posibles riesgos.
Descripción del Problema
Revisar documentos largos antes de estimar o planificar un proyecto consume tiempo y puede ocultar riesgos importantes. BriefGen-AI automatiza una primera lectura estructurada para acelerar el analisis.
Arquitectura
Arquitectura separada entre frontend Next.js y API Express. El endpoint `/api/analyze` recibe PDFs mediante Multer, aplica validacion de tipo y tamano, procesa el archivo en memoria, extrae texto, ejecuta chunking recursivo y llama a Gemini desde LangChain.js. Incluye health check, CORS configurable y despliegue Docker para el backend.
Características Clave
- Carga de PDFs con drag and drop y validacion de archivo
- Extraccion de texto y chunking recursivo
- Analisis con LangChain.js y Google Gemini
- Respuesta JSON con resumen, requisitos, stack y riesgos
- Procesamiento en memoria sin almacenamiento persistente de archivos
- Opciones de copiar o descargar resultados
Desafíos
- Controlar documentos grandes dentro de limites de tokens y tamano
- Normalizar salidas de IA en una estructura JSON util
- Manejar errores de PDFs sin texto extraible o archivos invalidos
- Separar correctamente responsabilidades entre UI, API y servicio de analisis
Resultados
Herramienta funcional para transformar PDFs en un analisis inicial estructurado, util para discovery tecnico, lectura de briefs y evaluacion temprana de riesgos.