BriefGen-AI - AI Document Analysis
Application for analyzing PDFs with Next.js, Express, LangChain, and Google Gemini, returning summaries, requirements, stack, and risks in structured format.
Technical Overview
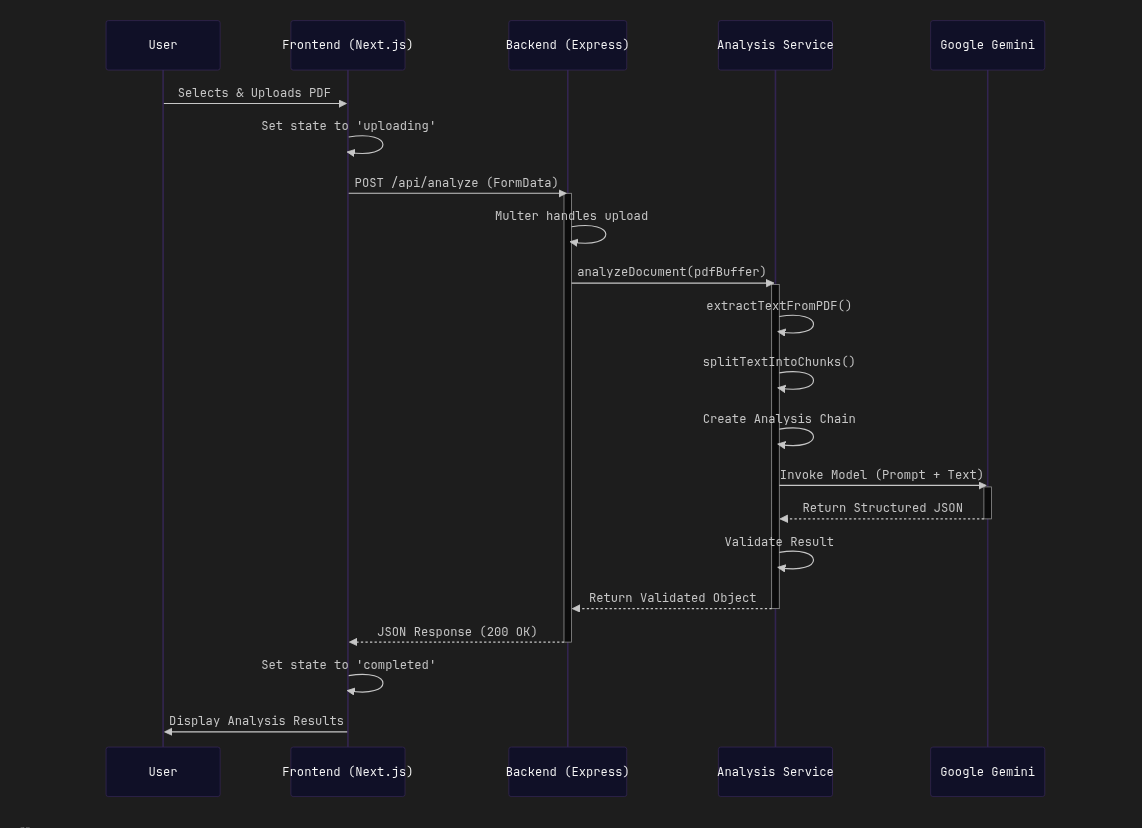
BriefGen-AI processes PDF documents such as briefs, RFPs, and technical documents to extract actionable information. The frontend is built with Next.js 14, React 18, TypeScript, Tailwind CSS, and shadcn/ui. The backend uses Node.js and Express to receive files, validate them, extract text, split it into manageable chunks with LangChain, and query Google Gemini. The response is normalized as JSON with a summary, key requirements, detected technologies, and potential risks.
Problem Statement
Reviewing long documents before estimating or planning a project takes time and can hide important risks. BriefGen-AI automates an initial structured reading to accelerate analysis.
Architecture
Separated architecture between a Next.js frontend and an Express API. The `/api/analyze` endpoint receives PDFs through Multer, validates type and size, processes the file in memory, extracts text, runs recursive chunking, and calls Gemini through LangChain.js. It includes a health check, configurable CORS, and Docker deployment for the backend.
Key Features
- PDF upload with drag and drop and file validation
- Text extraction and recursive chunking
- Analysis with LangChain.js and Google Gemini
- JSON response with summary, requirements, stack, and risks
- In-memory processing without persistent file storage
- Options to copy or download results
Challenges
- Handling large documents within token and file-size limits
- Normalizing AI output into a useful JSON structure
- Managing errors from PDFs without extractable text or invalid files
- Separating responsibilities across UI, API, and analysis service
Outcomes
Functional tool for transforming PDFs into an initial structured analysis, useful for technical discovery, brief review, and early risk evaluation.